深度学习框架在计算机视觉应用背后的挑战 软硬件协同开发的新命题
计算机视觉作为人工智能领域的核心分支,已广泛应用于安防监控、自动驾驶、医疗影像、工业质检等众多场景。这些应用的蓬勃发展,极大地推动了深度学习技术的进步,同时也对支撑其运行的深度学习框架提出了前所未有的挑战。这些挑战不仅体现在算法模型本身,更深刻地映射到计算机软件与硬件的协同开发与优化上。
一、 软件层面的核心挑战
- 模型复杂性与框架灵活性:现代计算机视觉模型(如Transformer、大型卷积神经网络)结构日益复杂,参数量巨大。深度学习框架需要提供高度灵活且高效的编程接口与计算图构建能力,以支持研究人员快速设计、实验和部署新模型,同时确保前向推理与反向传播的计算正确性与效率。
- 计算效率与优化编译:视觉任务通常涉及高分辨率图像或视频流,计算密集度高。框架需要集成先进的图优化、算子融合、内存复用等技术,并具备强大的即时(JIT)编译或提前(AOT)编译能力,将高级模型描述转化为底层硬件高效执行的指令,以最大化利用计算资源。
- 部署的多样性与易用性:从云端服务器到边缘设备(如手机、摄像头、车载芯片),视觉模型的部署环境差异巨大。框架需提供统一的模型表示(如ONNX),并支持跨平台、跨硬件的模型转换、量化和压缩工具链,以降低从训练到部署的工程门槛。
- 动态性与实时性需求:许多视觉应用(如自动驾驶感知、实时视频分析)要求低延迟和高吞吐量。框架需要高效处理动态输入(如可变尺寸图像)、支持流式处理,并能在严格的时间约束下完成计算。
二、 硬件层面的驱动与约束
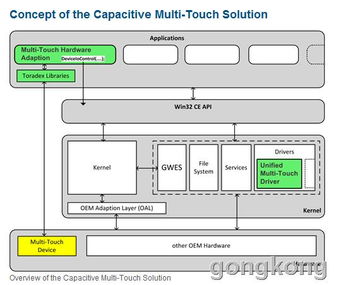
- 硬件架构的多元化:除了传统的CPU,深度学习计算已广泛依赖于GPU、NPU、TPU、FPGA等多种专用加速器。每种硬件都有其独特的计算单元、内存层次和指令集。深度学习框架必须能够抽象底层硬件差异,提供统一的编程模型,同时又能针对特定硬件进行深度优化,发挥其峰值算力。
- 内存与带宽瓶颈:视觉模型参数量大,中间激活值也占用海量内存。硬件的内存容量和带宽常常成为性能瓶颈。框架的优化器需要精打细算地进行内存分配与调度,利用硬件特性(如GPU的共享内存、高速缓存)来减少数据搬运开销。
- 能效比要求:特别是在移动端和边缘端,硬件算力和电池容量有限。框架需要与硬件紧密结合,支持模型剪枝、量化(如INT8、FP16)、知识蒸馏等技术,在保证一定精度的前提下,大幅降低模型的计算量与存储需求,提升能效比。
三、 软硬件协同开发的必然趋势
面对上述挑战,传统的“软件框架先行,硬件适配跟进”的模式已显乏力。计算机视觉应用的深入发展,正催生着软硬件协同设计的新范式:
- 硬件感知的软件优化:深度学习框架越来越多地集成硬件特性感知的优化器。例如,自动生成针对特定芯片微架构高度优化的计算内核,或者根据硬件的内存布局自动调整数据排布。
- 软件驱动的硬件设计:硬件设计(如新型AI芯片)越来越多地以主流深度学习框架所定义的计算模式和算子为核心进行定制,设计专用的计算单元、内存系统和互联架构,从根源上提升关键视觉任务(如卷积、注意力机制)的执行效率。
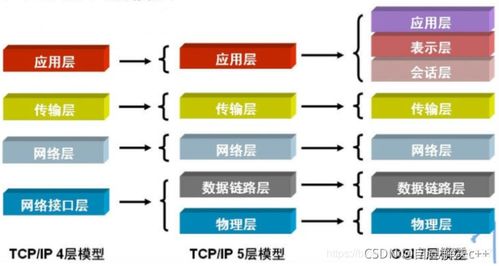
- 统一中间表示与编译器栈:如MLIR(Multi-Level IR)等项目的兴起,旨在构建一个可扩展的编译器基础设施,在高层框架计算图与底层硬件指令之间建立多层中间表示,使软硬件之间的优化与映射更加系统化和自动化。
结论
计算机视觉应用的边界正不断拓展,其对性能、精度、延迟和能效的严苛要求,构成了对深度学习框架的全面考验。这一挑战的本质,是推动深度学习系统从“软硬件分离”走向“软硬件协同”。未来的深度学习框架,将不再是纯粹的软件抽象层,而是演变为一个连接算法创新与硬件算力的智能、自适应桥梁。只有通过软件与硬件的深度融合与协同创新,才能充分释放计算潜力,支撑起下一代更强大、更普及的计算机视觉应用。
如若转载,请注明出处:http://www.xuelunyu.com/product/40.html
更新时间:2026-06-19 21:21:45